INTRODUCTIONWord recognition tests are extremely important in audiological diagnosis. The audiological battery is considered incomplete without speech recognition tests.
Speech understanding skill is one of the most important measurable aspects in human hearing function. Speech tests can assess speech understanding in appropriately controlled conditions 1.
The tests used to measure auditory performance of subjects in speech recognition tasks use isolated stimuli, being that monosyllable or disyllable words are the most frequently used ones 2.
In Portuguese, speech recognition tests are traditionally made with monosyllables. However, the preparation of those lists is not based on phonetic balance, since Portuguese is not a phonetic language. There are basically two lists that have been used in speech recognition tests 3, 4. More recently, other authors have also suggested new lists to be used 5-7.
Speech recognition is followed by a combination of acoustic, linguistic, semantic and circumstantial cues 8. However, upon hearing in favorable conditions, some of those cues are excessive and may be discarded. So that the message can be effectively transmitted, there is redundancy of acoustic cues used by the listener depending on the situation and the communication context. This is what happens, for example, in situations of conversation in the presence of background noise.
In daily clinical audiology practice, we normally receive subjects with the same level and configuration of sensorineural hearing loss who have substantially different skills concerning speech perception. There is relatively poor correlation between pure tone thresholds and speech intelligibility in subjects with sensorineural hearing loss. Probably, other factors in addition to auditory sensitivity interfere in speech perception 9.
Thus, it is extremely important to study the performance of listeners in less favorable hearing conditions and to check which processes can interfere in the speech perception of these subjects.
Most of the subjects with high frequency hearing loss (higher than 3000Hz) can refer little or no difficulty to understand speech in quiet, since in these situations there are other cues that can be used by them to understand speech. However, in noise or in the presence of adverse conditions, such as for example when speech is distorted, the subject may present many difficulties to understand speech, since the number of cues is significantly reduced, leading to the use of only those cues available in the situation. It justifies the concern of avoiding measuring speech recognition only in situations of acoustically treated rooms, in which stimuli are under control, but also measuring in situations that are closer to real life 10.
Two types of noise are recommended in the assessment of speech perception: competitive speech noise and environmental noise, being that competitive speech noise plays a more significant effect in speech perception when compared to environmental noises in general 11.
Many tests have already been developed taking it in consideration, among which we can mention SPIN (speech perception in noise), speech reception thresholds for sentences in noise 13, Hagerman's test 14 (lists of sentences in noise) and Dantale II15 (lists of sentences in noise adapted to Danish). In these tests, the most frequently used noise is "babble" (speech mumbling noise).
In Brazil, speech recognition test was standardized with white noise 10, 16. Other authors recommended the use of competitive noise of cafeteria 17, competitive noise with speech spectrum and amplitude modulations 18, and finally, cocktail party noise 19-21. The latter is speech spectrum noise associated with noise of a party situation.
Speech noise interferes more than continuous noise. This interference is greater owing to the fact that speech babble has false cues and thus increases the requirement for attention and memory use involved in the understanding process or speech perception process 10.
A study compared Speech Recognition Index (SRI) obtained with two types of white noise and cocktail party noise in young subjects with normal hearing and found that the latter was more disturbing to speech intelligibility at the same signal-to-noise ratio. These findings were confirmed by two forms of investigation: SRI and speech intelligibility judgment 19.
Speech recognition in low redundancy conditions, such as speech recognition in noise, has been widely investigated in different populations of young and elderly subjects, with and without hearing loss.
Elderly subjects, with and without hearing loss, seem to have considerable difficulty in understanding speech that is acoustically distorted 22, 23. A large number of studies have supported the notion that speech recognition difficulties in elderly are part of loss of hearing sensitivity associated with age 24. Other studies pointed to the fact that elderly have worse performance than young people in speech in noise 25; in speech distorted by reverberation 22; and in compressed speech 23, even in groups that have similar auditory sensitivity. These findings suggest that other factors, in addition to thresholds' changes, contribute to the decrease of speech recognition in the elderly.
When noise or any other distortion is added to the hearing situation, worse performances are observed in elderly people when compared to young people. Speech recognition in noise was investigated by SPIN test in young and elderly patients with normal hearing; young people whose thresholds were masked similarly to a hearing loss, and elderly people with hearing loss and the results showed worse performance in elderly people with normal hearing when compared to young people with normal hearing and young people with simulated hearing loss 26. A plausible explanation to this difference in performance is babble noise, which seems to have greater distraction effect in the older population than in the young one.
The skills to ignore irrelevant stimuli seem to reduce as age increases 27. A general explanation to the difficulty in processing related to age would be the diffuse effect of aging that would primarily affect the central nervous system, reducing the functional correlation of signal/noise, that is, the elderly would need greater amount of signal (speech) to codify messages as opposed to noise (other competitive sounds). This reduction would result from the effects of reduction of codification of signal and general level of signal 28.
Speech recognition in noise can be seen as a task that demands both use of memory and selective attention, since the listener needs to focus attention on the message (key word) and remember speech information stored in the memory, at the same time ignoring irrelevant information.
This study investigated speech recognition in quiet and in noise for two types of noise: wide spectrum white noise and cocktail party noise in adult and elderly subjects with hearing loss in high frequencies, in order to check whether there would be a difference in performance for situations of speech recognition in quiet, and in the presence of two types of noise, in addition to comparing performance of the groups for each task.
MATERIAL AND METHODSubjects
The study comprised sixty subjects who were distributed in three groups: adults with normal hearing (G1), adults with hearing loss (G2) and elderly with hearing loss (G3).
All subjects participating in the study were informed about its objective and signed a free informed consent. The study was approved by the Research Ethics Committee of HCRP/USP.
Group 1 comprised twenty adult women with normal hearing. Ages ranged from 21 to 38 years, mean age of 23.30 years. Group 2 comprised twenty adults being eighteen men and two women, whose ages ranged from 29 to 50 years, mean age of 40.45 years. The subjects presented high frequency sensorineural hearing loss from 3000Hz. Finally, Group 3 was formed by 20 elderly patients, ten male and ten female subjects, whose ages ranged from 60 to 77 years, mean age of 66.85 years. The subjects in groups 2 and 3 presented similar audiometric configuration (confirmed by variance analysis - ANOVA). See mean values of frequency and speech reception thresholds for both ears in Table 1 and results of immittanciometry in Table 2.
Material
To conduct the tests, we used two-channel audiometer AC 30 (Kamplex), middle ear analyzer Az7 (Interacustics), soundproof booth, portable Compact Disc player SL-S145 XBS Panasonic and a CD, which contained the lists of words edited with noise.
Stimuli
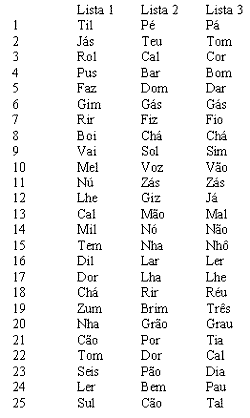
We used three lists of monosyllables with 25 items, one to conduct Speech Recognition Index (SRI) in quiet 3 (List 1) and respectively two others for SRI in wide spectrum white noise and in cocktail party noise 4 (Lists 2 and 3). Each list was edited in two random orders, one to each ear. Lists are presented in Annex 1.
CD Preparation
The recording was conducted in a professional studio. The narrator was male, native speaker of standard Portuguese and presented normal speech pace during the recording. His voice presented speech frequency (Fo) of about 125 Hz measured by Computer Speech Laboratory. The voice was initially recorded in the computer hard disk, and digitalized to better reproduce it. We used multidirectional microphone placed 15cm from the narrator. Before the utterance of each stimulus, the narrator said the number of the stimulus. The material, after recording, was analyzed and processed by the computer so as to have artifacts removed and to result in a narrow dynamic range sample, without affecting speech characteristics. Noises, wide spectrum white noise and cocktail party, were originally recorded in a compact disc (CD), directed to the computer hard disk, in which they were stored. From then on, the material was edited. Speech stimulus was then introduced in one channel and noise in the other. The introduction of the noise occurred in the moment in which the stimulus was uttered, interrupted simultaneously at the end of the stimulus. Both channels were monitored considering peak and dynamic range controls so as to allow simultaneous use of both stimuli (speech and noise), with control of channel intensity. After edition of the material, the final CD was burned.
Protocol
The subjects were submitted to ENT assessment, followed by audiological battery comprising pure tone audiometry, air and bone thresholds, speech recognition thresholds (SRT) and immittanciometry. Next, we conducted speech recognition index in quiet and in noise.
To conduct SRI, we used the counterbalancing method in the three groups, being that each 10 subjects in each group started SRI with white noise and the other half with cocktail party noise.
Speech signal generated by the CD was presented at 40dB above pure tone mean of 500, 1000 and 2000 Hz. Both noises used were also presented ipsilaterally at the same intensity of speech signal, which characterized a signal-to-noise ratio of 0dB. Speech recognition test was started on the left and followed by the right ear.
Data Analysis
To analyze data, we computed number of mistakes for each test situation: speech recognition in quiet, speech recognition in cocktail party noise and in wide spectrum white noise. Later, we calculated the average number of mistakes by group. We applied repetitive measures of variance analysis (ANOVA) and post hoc multiple comparison test of Tukey (HSD)29 to compare the performance of the groups. Results were considered statistically different when the level of significance was below 0.05.
RESULTSThe tests of speech recognition in quiet were calculated based on number of mistakes. In Group 1 the mean value of number of mistakes was 0.25, with standard deviation of 0.44 to the left and 0.15, with standard deviation of 0.37 to the right. In group 2, mean values of mistakes were 1.3 to the left, with standard deviation of 1.42 and 1.0 to the right, with standard deviation of 1.86. In Group 3, mean values were 1.7, standard deviation of 1.30 to the left, and 0.7, standard deviation of 0.86 to the right.
Post hoc multiple comparison test of Tukey (HSD) among groups tested in quiet only showed statistically significant difference in the comparison between the left (first tested ear): G1 X G3, p = 0.001 and G1 X G2, p = 0.01. There were no statistically significant differences on the left for comparisons between G2 X G3, p > 0.05. To the right ear, there were no statistically significant differences among the groups (p >0.05).
Speech recognition index obtained with wide spectrum white noise showed a large number of mistakes in all groups. In Group 1, the mean number of mistakes was 8, with standard deviation of 1.84 to the left; and 8.4, with standard deviation of 1.64 to the right. In Group 2, mean values were 9.75 to the left, with standard deviation of 2.24; and 8.6, with standard deviation of 2.58 to the right. In Group 3, mean values of mistakes were 11.05, with standard deviation of 3.35 to the left; and 9.9, with standard deviation of 3.02 to the right.
Post hoc multiple comparison test of Tukey (HSD) among the groups showed only statistically significant differences in comparison between G1 X G3, p = 0.01 on the left. To the other comparisons between G1 X G2; G2 X G3 on the left; and among all comparisons on the right, there was no statistically significant difference (p > 0.05).
Speech recognition index in cocktail party noise showed a large number of mistakes, but they were evident in the groups with hearing loss (groups 2 and 3). In Group 1, the mean number of mistakes was 8.55, with standard deviation of 2.63 to the left; and 6.55, with standard deviation of 2.44 to the right. In Group 2, mean values of mistakes were 11.9 with standard deviation of 3.75 to the left; and 10.85, with standard deviation of 2.91 to the right. In Group 3, mean value of mistakes were 14.6; with standard deviation of 3.63 to the left; and 12.75, with standard deviation of 4.10 to the right. Figures 1 and 2 show the mean number of mistakes and the respective standard deviations for the three tasks of speech recognition in both ears and for the three groups.
Post hoc multiple comparison test of Tukey (HSD) among the groups for SRI in cocktail party noise showed statistically significant difference in the comparison of groups to the left ear: G1 X G3, p = 0.001; G1 X G2, p = 0.007; and G2 X G3, p = 0.037. As to comparison between right ear, there was also statistically significant difference between G1 X G3, p = 0,000; and G1 X G2, p =0,000. There was no statistically significant difference for G2 X G3 on the right ear (p > 0.05).
Repetitive measure variance analysis for data obtained with the speech recognition test showed statistically significant difference for group factor F (2.57) = 16.72, p = 0.000. Post hoc multiple comparison test of Tukey (HSD) showed difference between G1 X G2, p = 0.01 and G1 X G3, p = 0.05. However, there was no significant difference between G2 X G3, p > 0.05.
Comparison between ears proved to be significant in: F (1.2) = 31.190, p = 0.000; as well as in conditions of noise: F (1.2) = 763.341, p = 0.000. Interactions between noise and group were highly significant: F (2.57) = 16.735, p = 0.000; as well as between noise and ear: F (2.57) = 11.519, p = 0.001, indicating dependency of these variables.
DISCUSSIONThe results obtained with speech recognition index in quiet showed that there was no difference in performance in the three groups, since auditory thresholds in speech frequencies were preserved. There was statistically significant difference only between the elderly group and the normal hearing adult group in the first tested ear.
The mean number of mistakes in both ears for all groups was not higher than two, which corresponds to speech recognition index higher than 92%, values considered within the normal range. When we reach an index equal or greater than 92%, no speech recognition damage is expected 30.
Despite the very similar rates, they may not correspond to the communication situation experienced by subjects without hearing loss in high frequencies since speech does not occur isolated from other auditory stimuli.
In fact, in ENT practice, many patients commonly complain of difficulties to understand speech. However, upon conducting SRI in quiet, most of them present few mistakes, which correspond to indexes of 88 to 100%, values that show no difficulty in speech recognition, which are normally found in subjects with auditory disorders or in those that have conductive problems.
These findings indicate that speech recognition index in quiet is not a good predictor of difficulties experienced by people with high frequency hearing loss. There is poor correlation between pure tone auditory thresholds and speech intelligibility in subjects with sensorineural hearing loss, since other factors can interfere in the performance of subjects 9.
Results of speech recognition in the presence of white noise showed very high number of mistakes in all groups. Regardless of hearing loss, the groups behaved similarly, demonstrating that hearing loss has little effect over SRI with this type of noise. The only situation in which there was statistically significant difference in performance was in the elderly group, which presented greater number of mistakes when compared to the group of adults without hearing loss in the first tested ear.
Among these results, we can highlight the large number of mistakes in the group with normal hearing. These values differ from those of other studies in which they used the noise from the audiometer 10, 16, 19. The difference was probably due to the white noise used in our study.
White noise is a broadband noise that contains energy in the range of 100 to 10,000Hz, being that the most effective area is 6000Hz, abruptly decreasing after it 31. However, white noise used in the present study was reproduced in a CD track and its acoustic analysis conducted later showed broadband energy strongly concentrated up to 10,000Hz, quickly dropping after it. Based on these data, we can suggest that the difference in performance present in this study compared to previous studies in adult subjects with normal hearing is a result of the fact that the spectrum noise was higher, and therefore, it has masked some phonemes such as fricatives and plosives in the three groups, dropping prevision skills for words, that is, linguistic redundancy was affected in all groups and interfered more in speech recognition.
If speech tests with white noise measure auditory closure skills 32, groups showed similar skills in auditory closure in this task.
Results of speech recognition with cocktail party noise demonstrated significant difference of performance in the three groups for both ears. However, there was greater difference between performance in the group with normal hearing when compared to the other two groups with loss, evidenced by ANOVA.
The number of mistakes found in the group with normal hearing (8.55) did not differ from the results found by Mantelatto (1998)19 in similar test conditions (9.45).
In fact, speech recognition index in noise is worse for those with hearing loss, when compared to normal hearing subjects 12. Subjects with sensorineural hearing loss have problems to recognize speech in a signal-to-noise ratio between -3dB and +6dB, even when speech level is above auditory thresholds 13.
It was also observed that in addition to higher number of mistakes for cocktail party noise, standard deviations were also higher, indicating that in the three groups some people had more harmful effects on speech perception with this type of noise.
Tests that use competitive speech noise, such as the case of cocktail party, investigate auditory figure-ground skills, since subjects have to separate key information from noise. Therefore, speech competitive noise has been used in studies of speech recognition in noise 12, 18, 19-21.
Cocktail party noise, comparing to wide spectrum white noise, seems to have been more sensitive in patients with hearing loss, since their performance was worse for this type of noise. It confirms the hypothesis that this type of noise has a disturbing effect for speech intelligibility, contributing to reduce extrinsic message redundancy.
Moreover, speech recognition obtained with cocktail party noise allowed the differentiation not only of the group with normal hearing and the group with hearing loss, but also evidenced the difference in performance between the adult and elderly groups with loss. Variance analysis - ANOVA - determined a relation of dependence between noise and the group, indicating that performance of the group is affected by noise, that is, noise played a more serious effect in groups with hearing loss and the age factor has equally interfered.
Another study has also compared performance of young and elderly with similar audiometric configurations in speech recognition in noise in signal-to-noise ratio of zero and found worse performance in elderly 33. The findings confirmed that age influenced speech recognition in distorted speech signals. The greater the distortion, the greater the effect observed in age.
The results sustained the idea that performance in the elderly is worse than that of young people with the same auditory sensitivity, indicating that other factors are involved in speech recognition in noise, in addition to auditory sensitivity in peripheral organ (inner ear).
Speech recognition in noise can be seen as a task that demands both use of memory and selective attention, because hearing people have to focus attention on the message and remember speech information by heart, at the same time ignoring irrelevant information. Elderly auditory processing is affected not only by auditory sensitivity of loss, but also by memory and decision cognitive processes 26, 28.
Another important finding in this study was the difference between the first and second tested ears, found in all groups tested for speech recognition. The results were compatible with other studies, which have also found differences concerning the first and second ears, regardless of which ear has started the test. The results confirmed the effect of learning 10, 16. Even though monosyllables have been presented in random order, subjects can get used to hearing speech in noise and in the second presentation they improve their performance. Another feasible explanation is that the performance of subjects improves because they are used to listening to words in noise. Probably, other central mechanisms favor improvement of their performance, such as selective attention processes, required in competitive noise tasks.
CONCLUSIONThe findings in the present study pointed to the fact that speech recognition index in quiet, even though considered an important instrument of assessment, cannot be the single tool used for speech discrimination. Considering that communication happens in a social environment, with other competitive stimuli, there should also be speech recognition in noise so as to check the extension of the communication problem caused by the hearing loss.
Speech recognition indices obtained with noise have evidenced a decrease in number of correct answers. However, the results obtained with wide spectrum white noise did not define differences among the groups.
According to the results obtained in this study competitive noise, such as the case of cocktail party noise, was more effective to show the effects of hearing loss and aging in speech perception.
SRI poor performance of the elderly with hearing loss in the presence of cocktail party noise evidenced the difficulty elderly people have in auditory figure-ground tasks when compared to young people with similar loss. The results can also be related to functional signal-to-noise ratio present in the elderly.
Even though the results obtained with cocktail party noise in this study are very relevant, more studies are required, including standardization of use in large populations, before its application in clinical practice.
REFERENCES1. Penrod JP. Testes de Discriminação Vocal. In: Katz J. Tratado de Audiologia Clínica. 4a Ed. São Paulo: Editora Manole; 1999. p. 146-62.
2. Lacerda AP. Audiologia Clínica. Rio de Janeiro: Guanabara Koogan; 1976.
3. Pen MG, Mangabeira-Albernaz PL. Desenvolvimento de testes para logoaudiometria: discriminação vocal. Anales II Congresso Pan Americano de Otorrinolaringologia Y Broncoesofasologia: 1970; Lima-Peru. (2): 223-6.
4. Santos TMM, Russo ICP. A prática da audiologia clínica. 3ª Ed. São Paulo: Cortez; 1986.
5. Chaves AD, Nepomuceno LA, Rossi AG, Mota HB, Pillo L. Reconhecimento de fala: Uma descrição de resultados obtidos em função do número de sílabas dos estímulos. Pró Fono 1999; 11(1): 53-8.
6. Harris RW, Goffi MVS, Pedalini MEB, Gygi MA. Reconhecimento de Palavras dissilábicas Psicometricamente equivalentes no português Brasileiro faladas por indivíduos do sexo masculino e do sexo feminino. Pró Fono 2001; 13(2): 249-62.
7. Roll E, Wallenhaupt D, Ramos APF, Menegotto IH. Novas Listas de Monossílabos para a avaliação do reconhecimento de fala. Pró Fono 2003; 15 (2): 159-68.
8. Gama MR. Percepção da fala: uma proposta de avaliação qualitativa. São Paulo: Pancast; 1994.
9. Yoshioka P, Thornton AR. Predicting speech discrimination from audiometric thresholds. J Speech Hear Res 1980; 23: 814-27.
10. Schochat E. Percepção de fala: Presbiacusia e perda auditiva induzida pelo ruído. [Tese de Doutorado]. São Paulo: FFLCH/USP; 1994.
11. Sanders DA. Aural rehabilitation. New Jersey: Prentice Hall; 1982.
12. Kalikow DN, Stevens KN, Elliot, LL. Development of a test of speech intelligibility in noise using sentence materials with controlled word predictability. J Acoust Soc Am 1977; 61: 1337- 51.
13. Plomp R, Mimpen A. Speech-reception threshold for sentences as a function of age and noise level. J Acoust Soc Am 1979; 66: 1333-42.
14. Hagerman B. Sentences for testing speech intelligibility in noise. Scand Audio l 982 a; 11: 79-87.
15. Wagener K, Josvassen JL, Ardenkoer R. Design, optimization and evaluation of a Danish sentence test in noise. Intern J Audiol 2003; 42; 10-17.
16. Pereira LD. Audiometria verbal: teste de discriminação vocal com ruído. [Tese de Doutorado]. São Paulo: Escola Paulista de Medicina; 1993.
17. Costa EA. Audiometria tonal e testes de reconhecimento de fala. Estudo comparativo para aplicação em audiologia ocupacional. Acta awho 1992; 11: 137-42.
18. Costa EA. Desenvolvimento de Teste de Reconhecimento da Fala, com ruído, em português do Brasil, para aplicação em audiologia ocupacional. [Tese de doutorado]. Campinas: Faculdade de Ciências Médicas/Unicamp; 1998.
19. Mantelatto SAC. Percepção da Inteligibilidade de Fala por Sujeitos Jovens com audição normal frente à ruídos competitivos. [Dissertação de Mestrado]. Ribeirão Preto: FFCLRP/USP; 1998.
20. Mantelatto SAC, Da Silva JA. Inteligibilidade de Fala e Ruído: Um estudo com sentenças do dia-a-dia. Pró Fono 2000a; 12: 48-55.
21. Mantelatto SAC, Da Silva J A. Efeitos de diferentes tipos de ruído na Inteligibilidade de Fala. Arq Bras Psicol 2000b; 52: 35-48.
22. Helfer K, Wilber LA. Hearing loss, aging, and speech perception in reverberation and noise. Journal of Speech and Hearing Research, (1990). 33, 149-55.
23. Gordon-Salant S, Fitzgibbons PJ. Temporal factors and speech recognition performance in young and elderly listeners. J Speech Hear Res 1993; 36: 1276-85.
24. Humes LE, Christopherson L. Speech identification difficulties of hearing-impaired elderly persons: The contribution of auditory processing deficits. J Speech Hear Res 1991; 34: 686- 93.
25. Dubno JR, Dirks DD, Morgan DE. Effects of age and mild hearing loss on speech recognition in noise. J Acoust Soc Am 1984; 76: 87-96.
26. Hargus SE, Gordon-Salant S. Accuracy of Speech Intelligibility Index Predictions for Noise-Masked Young Listeners With Normal Hearing and for Elderly Listeners with Hearing Impairment. J Speech Hear Res 1995; 38: 234-43.
27. McDowd JM, Fillon D. Aging, selective attention and inhibitory processes: A psychophysiological approach. Psychol Aging, 1992; 7: 65-71.
28. Salthouse TA. A theory of cognitive aging. New York: North-Holland; 1985.
29. Kirk RE. Statistics: An introduction. New York: Holt, Rinehart and Winston; 1990.
30. Jerger J, Speaks C, Trammell J. A new approach to speech audiometry. J Speech Hear Dis 1968; 33: 318.
31. Stockdell KG. Clinical Approaches to Measuring Discrimination Efficiency Via Word Lists. In: Rupp RR, Stockdell, KG. Speech Protocols in Audiology. New York: Grune & Stratton; 1980.
32. Pereira LD. Identificação de Desordem do Processamento Auditivo Central através de Observação Comportamental: Organização de Procedimentos Padronizados. In: Schochat E. Processamento Auditivo. São Paulo: Editora Lovise; 1996. p. 43-56.
33. Gordon-Salant S, Fitzgibbons, PJ. Comparing Recognition of Distorted Speech Using in Equivalent Signal-to-Noise ratio Index. J Speech Hear Res 1995 a; 38: 1150-56.
Table 1. Mean of auditory thresholds and the respective standard deviation by frequency in the three groups.
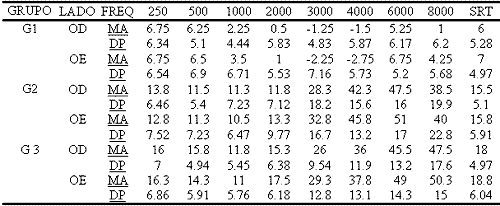
Note: arithmetic mean of auditory thresholds (MA) and standard deviation (DP) in groups: G1 - adult group with normal hearing; G2 - adult group with hearing loss; G3 - elderly group with hearing loss, and speech reception threshold (SRT); right ear (RE) and left ear (LE).
Table 2. Immittanciometry data for the three groups.

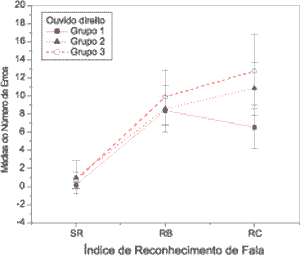 Figure 1.
Figure 1. Number of mistakes on the right ear in speech recognition index in quiet (SR), with white noise (RB) and cocktail party noise (RC) in the three groups.
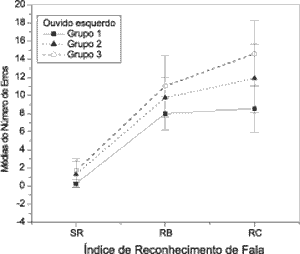 Figure 2.
Figure 2. Number of mistakes on the left ear in speech recognition index in quiet (SR), with white noise (RB) and cocktail party noise (RC) in the three groups.
Annex 1. List of monosyllables used for Speech Recognition Index.